

05. [20p] Orchestrare cu Docker SWARM
Am ajuns în punctul în care trebuie să lansăm site-ul în producție și stim că trebuie să ne preocupăm de aspecte precum scalabilitate (capacitatea de a suporta o încărcătură mai mare de lucru - un caz particular pentru perioada sărbătorilor), high-availability (Service-Level Agreement stabilit la 99%), redundanță sau toleranță la defecte (auto-healing). În forma standard, Docker Engine nu poate asigura niciunul din aspectele prezentate anterior, el furnizând doar un runtime de containerizare. Pentru a suporta constrângerile de producție, într-o formă autonomă și automată, este necesar un sistem de clusterizare și orchestrare. Soluția pe care o vom utiliza poartă numele de Docker SWARM.
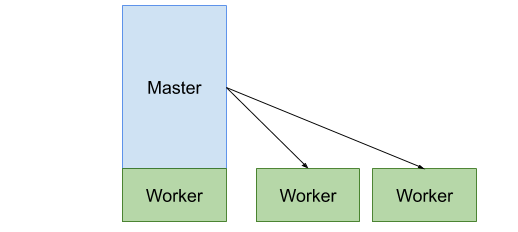
Docker SWARM este o soluție existentă în piață pentru orchestrarea de containere de tip Docker, în competiție cu platforme precum Kubernetes, Apache Mesos, OpenShift ș.a. Avantajul principal cu care vine platforma este ușurința în instalare și configurare, fiind un produs integrat nativ în Engine-ul de Docker. Din perspectivă arhitecturală, un cluster de Docker SWARM este alcătuit din două tipuri de noduri: Master Node - implementează nivelul de control, preluând cererile de deployment și monitorizând continuu starea cluster-ului Docker; Worker Node - asigură execuția containerelor solicitate de nivelul de control.

În cadrul laboratorului, vom utiliza o implementare simplificată, cu 2 noduri (1 master care are rol și de worker și 1 worker dedicat).
Înainte de a începe secțunea următoare, vom curăța nodurile de obiectele Docker create în exercițiile anterioare:
student@aldebaran:~$ docker rm -f rl-frontend rl-backend rl-database
student@aldebaran:~$ docker volume prune
student@aldebaran:~$ docker system prune
Totodată, pentru a simplifica terminologia utilizată în continuare, numim:
- MASTER - nodul/VM-ul care a fost ales ca Docker SWARM master
- WORKER - nodurile/VM-urile care au fost alese ca Docker SWARM workers
Pe nodul (VM) MASTER:
student@aldebaran:~$ docker swarm init --advertise-addr <IP interfață VM>
Din outputul anterior puteți obține comanda de join pe care o puteți utiliza pe nodurile care vor deservi ca workers. In cazul în care ulterior doriți să atașați noi noduri clusterului, puteți obține comanda anterioară astfel:
student@aldebaran:~$ docker swarm join-token worker
Pe celelalte noduri (pe nodurile WORKER):
student@aldebaran:~$ docker swarm join --token <SWARM cluster token> <IP interfață VM MASTER>:2377
Pe MASTER:
student@aldebaran:~$ docker node ls
În continuare vom vedea cum utilizarea unei soluții de orchestrare poate simplifica mentenanța, în producție, a unei aplicații critice, oferind capabilități și mecanisme de auto-healing, scheduling sau replicare.
Pe MASTER vom face o cerere de construire a unui tip special de setup de rețea, facil rulării aplicației noastre în mod distribuit, pe diverse noduri ale clusterului:
student@aldebaran:~$ docker network create -d overlay rlapp-overlay
Ulterior acestui pas, vom crea fiecare componentă a aplicație. În configurația curentă, toate cele 3 servicii vor fi conectate la același obiect de rețea:
student@aldebaran:~$ docker service create --name=rl-database \ -e MYSQL_DATABASE=rl-database \ -e MYSQL_USER=rl-user \ -e MYSQL_PASSWORD=rl-specialpassword \ -e MYSQL_ROOT_PASSWORD=root \ -e TZ=Europe/Bucharest \ --network=rlapp-overlay \ --replicas 1 \ mysql [...] student@aldebaran:~$ docker service create --name=rl-backend \ -e DB_SERVER=rl-database \ --network=rlapp-overlay \ --replicas 1 \ rlrules/docker-lab-backend [...] student@aldebaran:~$ docker service create --name=rl-frontend \ -e BACKEND_SERVER=rl-backend \ -p 8080:80 --network rlapp-overlay \ --replicas 1 \ rlrules/docker-lab-frontend [...]
Pentru a verifica distribuția serviciilor containerizate pe nodurile disponibilite:
student@aldebaran:~$ docker service ls
student@aldebaran:~$ docker service ps <numele serviciului>
Pentru a vedea doar acele containere care sunt în running state:
student@aldebaran:~$ docker service ps <numele serviciului> -f desired-state=running
Pentru simplitate, vom putea utiliza filtre:
student@aldebaran:~$ docker service ps $(docker service ls -q) -f desired-state=running
Din perspectiva unui orchestrator, Docker SWARM trebuie să se asigure că starea serviciilor pe care le-am lansat este consistentă. În cazul în care un serviciu(container) pică, SWARM trebuie să readucă starea clusterului la cea configurată. Pentru fiecare serviciu lansat anterior, am setat o constrângere particulară, care desemnează o stare a clusterului pe care o vrem constantă: --replicas 1. Să validăm faptul că Docker SWARM are capabilitatea de self-healing, aspect ce ne permite să stabilim prerogativele asigurării unui disponibilități crescute a aplicației web de partajare de imagini.
student@aldebaran:~$ docker service ps rl-frontend -f desired-state=running
În coloana NODE vedem unde a fost planificată execuția containerului asociat serviciului de frontend.
Pe nodul anterior obținut vom șterge container-ul de frontend:
student@aldebaran:~$ docker ps -f name=rl-frontend*
student@aldebaran:~$ docker rm -f <nume container sau id container>
Pe MASTER:
student@aldebaran:~$ watch docker service ps rl-frontend -f desired-state=running
Se poate vedea cum Docker SWARM a sesizat modificările aduse stării clusterului și a relansat unui nou container de frontend.
Într-un scenariu realist, simpla oprire a execuției unui container nu este singurul scenariu valid, ce trebuie luat în considerare, pentru a stabili dacă un serviciu este disponibil sau nu. Ce se întâmplă dacă aplicația rulează în continuare în container, dar intră într-un context de eroare ca de exemplu: o buclă infinită? Docker poate asigura mecanisme de probing, însă, într-un design matur, efortul de auto-healing trebuie susținut atât de runtime-ul de containerizare cât și de aplicația care rulează în container.
Știm, din incipit, faptul că în perioada sărbătorilor va exista un spike în utilizarea platformei de sharing de poze, astfel încât se conturează scenariul probabil ca serviciul de frontend, expus către exterior, să fie bombardat de cereri HTTP și să cedeze în fața numărului de conexiuni lansate către acesta. O soluție simplă pentru o astfel de problemă o reprezintă multiplicarea serviciului preconizat a fi afectat. Traficul HTTP va trebui, totodată, balansat echitabil între instanțele (replicile) serviciului multiplicat.
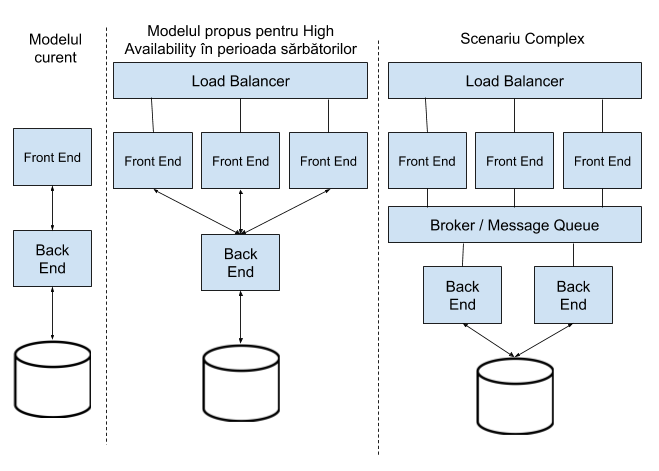
Cu Docker SWARM implementarea unui astfel de model de rețea redundant se poate realiza simplu, întrucât orchestratorul oferă posibilitatea creșterii numărului de replici ale unui container și totodată oferă nativ funcția de balansare între instanțele aplicației replicate. Să validăm aceste capabilități:
student@aldebaran:~$ docker service scale rl-frontend=3
student@aldebaran:~$ docker service ps rl-frontend -f desired-state=running
Din browser, incercați să vă conectați la aplicație utilizând IP-ul MASTER-ului atât dintr-o fereastră normală cât și dintr-o fereastră incognito/private.

Id-ul din colțul dreapta sus este id-ul unic al containerului în care rulează instanța de frontend. Întrucât am creat 3 replici ale aplicației, Docker SWARM va balansa traficul(load) către toate instanțele generate.
Mai mult, încercați să vă conectați la aplicație utilizând IP-ul Worker1 sau/și IP-ul Worker2. Funcționează? Un port expus în cadrul unui cluster Docker SWARM este disponibil pe întreaga componență a clusterului. Astfel, pentru accesa o aplicație expusă este suficient să cunosc una din adresele nodurilor clusterului și portul aplicației, fără a conta explicit unde rulează containerul.
Revenind la comparația dintre arhitecturi pe microservicii și arhitecturi monolite, observăm oportunitatea de scalare granulară, per serviciu/feature, cu care vine un model loosely coupled. În imaginea de mai jos se poate vedea metoda de scalare orizontală ce poate fi aplicată în ambele abordări: aplicații monolit și aplicații distribuite pe microservicii.
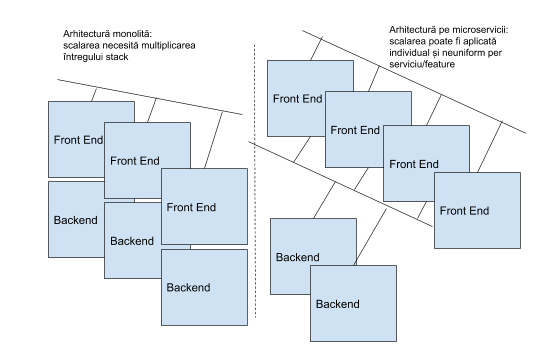
Deși aparențele pot sugera faptul că o aplicație modelată pe microservicii poate rezolva multe din problemele de producție, efortul dezvoltării unei aplicații pe microservicii poate fi semnificativ mai mare, amintind aici faptul că trebuie definit și dezvoltat un mecanism de comunicare slab cuplat (exemplu REST API), trebuie asigurate mecanisme pentru consistența datelor, în contexul scalării orizontale prin multiplicare (acces atomic asupra bazei de date etc.), trebuie realizată o distribuției echitabilă a efortului de procesare pe diversele replici, trebuie asigurate mecanisme de comunicare asincronă (așa cum se poate vedea în Scenariul complex de mai sus) etc. Cu toate acestea piața oferă framework-uri care să faciliteze dezvoltarea de aplicații construite peste o infrastructura de tipcloud și peste un model bazat pe microservicii. Spre exemplu: SpringBoot - framework de Java, Kabanero, lansat în vara anului 2019 de către IBM, oferă unelte pentru dezvoltarea directă peste Kubernetes etc.
Pentru a reveni la structura inițială, după trecerea perioadei sărbătorilor, putem face scale-down:
student@aldebaran:~$ docker service scale rl-frontend=1
student@aldebaran:~$ docker service ps rl-frontend
În acest laborator am iterat prin câteva concepte din lumea Docker și totodată am adresat probleme și concepte de system design. Echipa de RL speră să vi le însușiți și să vă fie benefice în carieră.
