

Laborator 10 - Networking
Obiectivele laboratorului
- Înțelegerea arhitecturii subsistemului de networking la nivelul nucleului Linux
- Deprinderea unor abilități practice de gestiune a pachetelor IP în cadrul unui filtru de pachete/firewall
- Familiarizarea cu modul de utilizare al sockeților la nivelul nucleului Linux
Cuvinte cheie
- stiva TCP/IP
- protocol
- adresă IP
- port
- socket, BSD socket, INET socket
PF_INET,AF_INETSOCK_STREAM,SOCK_DGRAMIPPROTO_TCP,IPPROTO_UDP- interfața loopback
bind,connect,listen,acceptsend,sendto,recv,recvfromstruct socket,struct sock,struct sk_buffhtons,htonl,ntohs,ntohl
Materiale ajutătoare
Noțiuni teoretice
Dezvoltarea Internet-ului a dus la creșterea exponențială a aplicațiilor de rețea și, drept consecință, la creșterea cerințelor de viteza și productivitate a subsistemului de rețea (networking) al unui sistem de operare. Subsistemul de networking nu este o componentă esențială a nucleului unui sistem de operare (kernel-ul Linux poate fi compilat fără suport de rețea). Este, însă, destul de puțin probabil pentru un sistem de calcul (sau chiar un dispozitiv embedded) să conțină un sistem de operare fără suport de rețea, datorită nevoii de conectivitate. Atât sistemele Linux (Unix), cât și Windows folosesc stiva TCP/IP. Nucleul acestora va conține implementate protocoalele până la nivelul transport inclusiv, urmând ca protocoalele de nivel aplicație să fie implementate în user-space (HTTP, FTP, SSH, etc.).
Networking în user-space
În user-space abstracția comunicației în rețea este socket-ul. Socket-ul abstractizează un canal de comunicație și este interfața de interacțiune cu stiva TCP/IP implementată în kernel. Unui socket IP i se asociază o adresă IP, protocolul de nivel transport utilizat (TCP, UDP etc) și un port. Apelurile uzuale pe un socket sunt: apelul de creare (socket), de inițializare (bind), de conectare (connect), de așteptare de conexiuni (listen, accept) și de închidere (close).
Comunicația în rețea se realizează prin intermediul apelurilor read/write sau recv/send pentru sockeți TCP, respectiv recvfrom/sendto pentru sockeți UDP. Operațiile de transmitere și recepție sunt transparente aplicației, lăsând la latitudinea nucleului încapsularea și transmiterea acestora în rețea. Este, însă, posibilă implementarea stivei TCP/IP în user-space folosind sockeți raw (opțiunea PF_PACKET la crearea unui socket), sau implementarea unui protocol de nivel aplicație în kernel (TUX web server).
Pentru mai multe detalii despre programarea în user-space folosind sockeți, consultați Beej's Guide to Network Programming Using Internet Sockets .
Linux networking
Kernel-ul Linux oferă trei structuri fundamentale pentru lucrul cu pachetele de rețea: struct socket, struct sock și struct sk_buff.
Primele două reprezintă abstractizări ale unui socket:
- struct socket este o abstractizare foarte aproape de user-space, adică de sockeții BSD folosiți pentru programarea aplicațiilor de rețea.
- struct sock sau INET socket în terminologia Linux este reprezentarea la nivel rețea a unui socket.
Cele doua structuri sunt corelate: struct socket conține un câmp de INET socket, iar struct sock are un BSD socket care îl deține.
Structura struct sk_buff este reprezentarea unui pachet de rețea și a stării acestuia. O astfel de structură este creată la sosirea unui pachet în kernel, fie din user-space, fie de la placa de rețea.
Structura socket
Structura struct socket este reprezentarea în kernel a unui socket BSD, operațiile care pot fi executate asupra acestuia fiind similare cu cele expuse de kernel aplicațiilor (prin apeluri de sistem). Operațiile comune de lucru cu sockeții (creare, inițializare/bind, închidere, etc.), rezultă în apeluri de sistem specifice; acestea operează asupra unei structuri de tipul struct socket.
Operațiile asupra struct socket sunt descrise în net/socket.c și sunt independente de tipul de protocoale de mai jos. Structura struct socket este, astfel, o interfață generică peste implementări particulare de operații de rețea. De obicei, numele acestor operații încep cu șirul sock_.
Operații asupra structurii socket
Operații asupra unui socket sunt:
Crearea
Crearea este asemănătoare apelului socket din user-space, dar socket-ul creat struct socket, va fi întors în parametrul res:
-
- funcție apelată pentru crearea unui socket în urma unui apel de sistem
socket;
-
- funcție apelată pentru crearea unui socket în kernel;
-
- funcție 'lite' cu eliminarea verificării parametrilor.
Parametrii acestor apeluri sunt următorii:
net, acolo unde este prezent este o referință la namespace-ul de rețea folosit; uzual îl vom inițializa la init_net;familyreprezintă familia protocoalelor utilizate în transferul informației; de obicei, acestea încep cu șirulPF_(Protocol Family); constantele care reprezintă familia de protocoale utilizate se găsesc în linux/socket.h, dintre care cea mai utilizată estePF_INET, pentru protocoalele TCP/IP.typereprezintă tipul de socket; constantele utilizate pentru acest parametru se găsesc în linux/net.h, dintre care cele mai utilizate suntSOCK_STREAMpentru o comunicație bazată pe conexiune între sursă și destinație șiSOCK_DGRAMpentru o comunicație fără conexiune.protocolreprezintă protocolul utilizat și este în strânsă legătură cu parametrul type; constatele utilizate pentru acest parametru se găsesc în linux/in.h, dintre care cele mai folosite suntIPPROTO_TCPpentru TCP șiIPPROTO_UDPpentru UDP.
Pentru crearea unui socket TCP în kernel se va apela:
struct socket *sock; int err; err = sock_create_kern(&init_net, PF_INET, SOCK_STREAM, IPPROTO_TCP, &sock); if (err < 0) { /* handle error */ }
iar pentru crearea unui socket UDP:
struct socket *sock; int err; err = sock_create_kern(&init_net, PF_INET, SOCK_DGRAM, IPPROTO_UDP, &sock); if (err < 0) { /* handle error */ }
Un exemplu de utilizare poate fi urmărit în codul handler-ului pentru apelul de sistem sys_socket:
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol) { int retval; struct socket *sock; int flags; /* Check the SOCK_* constants for consistency. */ BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC); BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK); BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK); BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK); flags = type & ~SOCK_TYPE_MASK; if (flags & ~(SOCK_CLOEXEC | SOCK_NONBLOCK)) return -EINVAL; type &= SOCK_TYPE_MASK; if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK)) flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK; retval = sock_create(family, type, protocol, &sock); if (retval < 0) goto out; return sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK)); }
Închiderea
Închiderea conexiunii (pentru socket cu conexiune) și eliberarea resurselor asociate:
voidsock_release(struct socket *sock)- această funcție va apela funcțiareleasedin câmpulopsal structurii socket-ului:
void sock_release(struct socket *sock) { if (sock->ops) { struct module *owner = sock->ops->owner; sock->ops->release(sock); sock->ops = NULL; module_put(owner); } //... }
Transmiterea/recepția unui mesaj
Transmiterea/recepția mesajelor se face cu ajutorul funcțiilor:
intkernel_recvmsg(struct socket *sock, struct msghdr *msg, struct kvec *vec, size_t num, size_t size, int flags);intkernel_sendmsg(struct socket *sock, struct msghdr *msg, struct kvec *vec, size_t num, size_t size);
Funcțiile de transmitere/recepție de mesaj vor apela ulterior funcția sendmsg/recvmsg din câmpul ops al socket-ului. Funcțiile ce conțin kernel_ ca prefix sunt folosite în cazul în care socket-ul este utilizat în cadrul kernel-ului.
Parametrii acestor funcții sunt următorii:
msg, o structura struct msghdr, ce conține mesajul de transmis/recepționat. Dintre componentele importante ale acestei structuri avemmsg_nameșimsg_namelen, care, pentru sockețiUDP, trebuie completate cu adresa la care se transmite mesajul (struct sockaddr_in)vec, o structură struct kvec, ce conține un pointer către buffer-ul ce conține datele și dimensiunea acestuia; după cum se poate observa, are o structură similară cu structura struct iovec (structura struct iovec corespunde datelor user space, iar structura struct kvec corespunde datelor kernel space)
Modul de lucru cu funcțiile de transmitere poate fi urmărit în cadrul handler-ului pentru apelul de sistem sys_sendto:
SYSCALL_DEFINE6(sendto, int, fd, void __user *, buff, size_t, len, unsigned int, flags, struct sockaddr __user *, addr, int, addr_len) { struct socket *sock; struct sockaddr_storage address; int err; struct msghdr msg; struct iovec iov; int fput_needed; err = import_single_range(WRITE, buff, len, &iov, &msg.msg_iter); if (unlikely(err)) return err; sock = sockfd_lookup_light(fd, &err, &fput_needed); if (!sock) goto out; msg.msg_name = NULL; msg.msg_control = NULL; msg.msg_controllen = 0; msg.msg_namelen = 0; if (addr) { err = move_addr_to_kernel(addr, addr_len, &address); if (err < 0) goto out_put; msg.msg_name = (struct sockaddr *)&address; msg.msg_namelen = addr_len; } if (sock->file->f_flags & O_NONBLOCK) flags |= MSG_DONTWAIT; msg.msg_flags = flags; err = sock_sendmsg(sock, &msg); out_put: fput_light(sock->file, fput_needed); out: return err; }
Câmpuri ale structurii socket
Structura struct socket:
/** * struct socket - general BSD socket * @state: socket state (%SS_CONNECTED, etc) * @type: socket type (%SOCK_STREAM, etc) * @flags: socket flags (%SOCK_NOSPACE, etc) * @ops: protocol specific socket operations * @file: File back pointer for gc * @sk: internal networking protocol agnostic socket representation * @wq: wait queue for several uses */ struct socket { socket_state state; short type; unsigned long flags; struct socket_wq __rcu *wq; struct file *file; struct sock *sk; const struct proto_ops *ops; };
Câmpuri importante sunt:
ops- structura ce conține pointeri la funcțiile specifice protocolului implementat;sk- INET socket-ul asociat.
Structura proto_ops
Structura struct proto_ops conține implementările operațiilor specifice protocolului implementat (TCP, UDP, etc.); funcțiile de aici vor fi apelate din funcțiile generice de lucru cu struct socket (sock_release, sock_sendmsg, etc.)
Structura struct proto_ops conține, așadar, o serie de pointeri de funcții pentru implementări specifice de protocol:
struct proto_ops { int family; struct module *owner; int (*release) (struct socket *sock); int (*bind) (struct socket *sock, struct sockaddr *myaddr, int sockaddr_len); int (*connect) (struct socket *sock, struct sockaddr *vaddr, int sockaddr_len, int flags); int (*socketpair)(struct socket *sock1, struct socket *sock2); int (*accept) (struct socket *sock, struct socket *newsock, int flags); int (*getname) (struct socket *sock, struct sockaddr *addr, int peer); //...
Inițializarea câmpului ops din struct socket se realizează în funcția __sock_create, prin apelul funcției create specifică protocolului; un apel echivalent este cel din implementarea funcției __sock_create:
//... err = pf->create(net, sock, protocol, kern); if (err < 0) goto out_module_put; //...
Se va realiza astfel instanțierea pointerilor de funcții cu apeluri specifice tipului de protocol asociat socket-ului. Apelurile sock_register și sock_unregister sunt folosite pentru completarea vectorului net_families.
Pentru restul operațiilor cu socketi (în afară de creare, închidere și transmitere/recepție mesaj, prezentate mai sus, în secțiunea Operații asupra structurii socket), se vor apela funcțiile date de pointerii din această structură. Spre exemplu, pentru operația bind, care asociază unui socket un port pe mașina locală, vom avea următoarea secvență de cod:
#define MY_PORT 60000 struct sockaddr_in addr = { .sin_family = AF_INET, .sin_port = htons (MY_PORT), .sin_addr = { htonl (INADDR_LOOPBACK) } }; //... err = sock->ops->bind (sock, (struct sockaddr *) &addr, sizeof(addr)); if (err < 0) { /* handle error */ } //...
După cum se poate observa, pentru transmiterea informațiilor legate de adresa și portul care se vor asocia socket-ului, se completează o structură struct sockaddr_in. 1)
Structura sock
Structura struct sock descrie un INET socket. O astfel de structură este asociată unui socket creat în user-space și, implicit, unei structuri struct socket. Structura este folosită pentru a menține informații despre starea unei conexiuni. Câmpurile structurii și operațiile asociate încep, de obicei, cu șirul sk_. Câteva câmpuri sunt prezentate mai jos:
struct sock { //... unsigned int sk_padding : 1, sk_no_check_tx : 1, sk_no_check_rx : 1, sk_userlocks : 4, sk_protocol : 8, sk_type : 16; //... struct socket *sk_socket; //... struct sk_buff *sk_send_head; //... void (*sk_state_change)(struct sock *sk); void (*sk_data_ready)(struct sock *sk); void (*sk_write_space)(struct sock *sk); void (*sk_error_report)(struct sock *sk); int (*sk_backlog_rcv)(struct sock *sk, struct sk_buff *skb); void (*sk_destruct)(struct sock *sk); };
sk_protocoleste tipul de protocol utilizat de socket;sk_typeeste tipul de socket (SOCK_STREAM,SOCK_DGRAM, etc.)sk_socketeste socket-ul BSD care îl deține;sk_send_headeste lista de structurisk_buffpentru transmitere;- pointerii de funcții de la sfârșit sunt callback-uri pentru diverse situații.
Inițializarea struct sock și atașarea acesteia la un socket BSD se face cu ajutorul callback-ului create din net_families (apelat in __sock_create). Mai jos este prezentat modul de
inițializare a structurii struct sock pentru protocolul IP, în cadrul funcției inet_create:
/* * Create an inet socket. */ static int inet_create(struct net *net, struct socket *sock, int protocol, int kern) { struct sock *sk; //... err = -ENOBUFS; sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern); if (!sk) goto out; err = 0; if (INET_PROTOSW_REUSE & answer_flags) sk->sk_reuse = SK_CAN_REUSE; //... sock_init_data(sock, sk); sk->sk_destruct = inet_sock_destruct; sk->sk_protocol = protocol; sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv; //... }
Structura sk_buff
Structura struct sk_buff (socket buffer) descrie un pachet de rețea. Câmpurile structurii conțin informații atât despre antetele și conținutul pachetelor cât și protocoalele utilizate, dispozitivul de rețea utilizat, pointeri către celelalte structuri struct sk_buff. O descriere sumară a conținutului structurii este prezentată mai jos:
struct sk_buff { union { struct { /* These two members must be first. */ struct sk_buff *next; struct sk_buff *prev; union { struct net_device *dev; /* Some protocols might use this space to store information, * while device pointer would be NULL. * UDP receive path is one user. */ unsigned long dev_scratch; }; }; struct rb_node rbnode; /* used in netem & tcp stack */ }; struct sock *sk; union { ktime_t tstamp; u64 skb_mstamp; }; /* * This is the control buffer. It is free to use for every * layer. Please put your private variables there. If you * want to keep them across layers you have to do a skb_clone() * first. This is owned by whoever has the skb queued ATM. */ char cb[48] __aligned(8); unsigned long _skb_refdst; void (*destructor)(struct sk_buff *skb); union { struct { unsigned long _skb_refdst; void (*destructor)(struct sk_buff *skb); }; struct list_head tcp_tsorted_anchor; }; /* ... */ unsigned int len, data_len; __u16 mac_len, hdr_len; /* ... */ __be16 protocol; __u16 transport_header; __u16 network_header; __u16 mac_header; /* private: */ __u32 headers_end[0]; /* public: */ /* These elements must be at the end, see alloc_skb() for details. */ sk_buff_data_t tail; sk_buff_data_t end; unsigned char *head, *data; unsigned int truesize; refcount_t users; };
unde:
nextșiprevsunt pointeri către următorul, respectiv precedentul element din lista de buffer-e;deveste device-ul care transmite sau primește buffer-ul;skeste socket-ul asociat buffer-ului;destructoreste apelul callback de dealocare a buffer-ului;transport_header,network headerșimac_headersunt offset-uri între începutul pachetului si începutul diverselor headere din pachet. Ele sunt menținute intern de diversele niveluri de procesare prin care trece pachetul. Pentru a obține pointeri către headere, folosiți una din următoarele funcții: tcp_hdr, udp_hdr, ip_hdr, etc. În principiu, fiecare protocol oferă o funcție de a obține o referință la header-ul respectivului protocol din cadrul unui pachet primit. De reținut: câmpulnetwork_headernu este setat decât după ce pachetul ajunge la nivelul rețea, iar câmpultransport_headernu este setat decât după ce pachetul ajunge la nivelul transport.
Structura unui antet IP (struct iphdr) are următoarele câmpuri:
struct iphdr { #if defined(__LITTLE_ENDIAN_BITFIELD) __u8 ihl:4, version:4; #elif defined (__BIG_ENDIAN_BITFIELD) __u8 version:4, ihl:4; #else #error "Please fix <asm/byteorder.h>" #endif __u8 tos; __be16 tot_len; __be16 id; __be16 frag_off; __u8 ttl; __u8 protocol; __sum16 check; __be32 saddr; __be32 daddr; /*The options start here. */ };
unde:
protocolreprezintă protocolul de nivel transport utilizat;saddrreprezintă adresa IP a nodului sursă;daddrreprezintă adresa IP a nodului destinație.
Structura unui antet TCP (struct tcphdr) are următoarele câmpuri:
struct tcphdr { __be16 source; __be16 dest; __be32 seq; __be32 ack_seq; #if defined(__LITTLE_ENDIAN_BITFIELD) __u16 res1:4, doff:4, fin:1, syn:1, rst:1, psh:1, ack:1, urg:1, ece:1, cwr:1; #elif defined(__BIG_ENDIAN_BITFIELD) __u16 doff:4, res1:4, cwr:1, ece:1, urg:1, ack:1, psh:1, rst:1, syn:1, fin:1; #else #error "Adjust your <asm/byteorder.h> defines" #endif __be16 window; __sum16 check; __be16 urg_ptr; };
sourcereprezintă portul sursădestreprezintă portul destinație
Structura unui antet UDP (struct udphdr) are următoarele câmpuri:
struct udphdr { __be16 source; __be16 dest; __be16 len; __sum16 check; };
sourcereprezintă portul sursădestreprezintă portul destinație
Un exemplu de accesare a informațiilor prezente în antetele unui pachet de rețea este următorul:
struct sk_buff *skb; struct iphdr *iph = ip_hdr(skb); /* IP header */ /* iph->saddr - source IP address */ /* iph->daddr - destination IP address */ if (iph->protocol == IPPROTO_TCP) { /* TCP protocol */ struct tcphdr *tcph = tcp_hdr(skb); /* TCP header */ /* tcph->source - source TCP port */ /* tcph->dest - destination TCP port */ } else if (iph->protocol == IPPROTO_UDP) { /* UDP protocol */ struct udphdr *udph = udp_hdr(skb); /* UDP header */ /* udph->source - source UDP port */ /* udph->dest - destination UDP port */ }
Conversii
În sisteme diferite, există mai multe variante pentru ordonarea octeților într-un cuvânt (Endianness), printre care: Big Endian (cel mai semnificativ octet primul) și Little Endian (cel mai puțin semnificativ octet primul). Având în vedere că o rețea interconectează sisteme cu platforme diferite, Internet-ul a impus o secvență standard pentru stocarea datelor numerice, numită network byte-order. Spre deosebire, secvența octeților pentru reprezentarea datelor numerice pe calculatorul gazdă se numește host byte-order. Datele primite/trimise din/în rețea sunt în formatul network byte-order și trebuie facută conversia între acest format și host byte-order.
Pentru conversie există urmatoarele macrodefiniții:
-
- convertește un întreg pe 16 biți din host byte-order în network byte-order (host to network short)
-
- convertește un întreg pe 32 de biți din host byte-order în network byte-order (host to network long)
-
- convertește un întreg pe 16 biți din network byte-order în host byte-order (network to host short)
-
- convertește un întreg pe 32 de biți din network byte-order în host byte-order (network to host long)
netfilter
Netfilter este denumirea interfeței de kernel pentru captura pachetelor de rețea cu scopul de modificare/analiză a acestora (pentru filtrare, NAT, etc.). Interfața netfilter este utilizată în user-space de iptables.
În kernel-ul Linux, captura de pachete folosind netfilter se realizează prin atașarea unor hook-uri. Hook-urile pot fi precizate în diferite locații din traseul urmat de un pachet de rețea în kernel, în funcție de necesitate. O organigramă cu traseul urmat de un pachet și zonele posibile de plasare a unui hook găsiți aici.
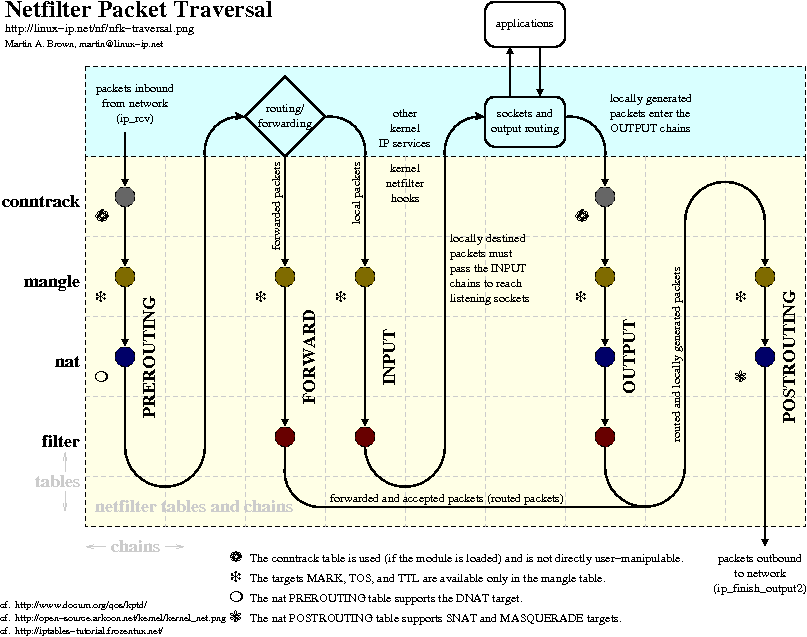{kind=link}
Header-ul inclus atunci când se folosește netfilter este linux/netfilter.h.
Un hook se definește prin intermediul structurii struct nf_hook_ops:
struct nf_hook_ops { /* User fills in from here down. */ nf_hookfn *hook; struct net_device *dev; void *priv; u_int8_t pf; unsigned int hooknum; /* Hooks are ordered in ascending priority. */ int priority; };
În cadrul structurii struct nf_hook_ops, pf este tipul pachetului (PF_INET, etc.). priority este prioritatea; prioritățile sunt definite în uapi/linux/netfilter_ipv4.h:
enum nf_ip_hook_priorities { NF_IP_PRI_FIRST = INT_MIN, NF_IP_PRI_CONNTRACK_DEFRAG = -400, NF_IP_PRI_RAW = -300, NF_IP_PRI_SELINUX_FIRST = -225, NF_IP_PRI_CONNTRACK = -200, NF_IP_PRI_MANGLE = -150, NF_IP_PRI_NAT_DST = -100, NF_IP_PRI_FILTER = 0, NF_IP_PRI_SECURITY = 50, NF_IP_PRI_NAT_SRC = 100, NF_IP_PRI_SELINUX_LAST = 225, NF_IP_PRI_CONNTRACK_HELPER = 300, NF_IP_PRI_CONNTRACK_CONFIRM = INT_MAX, NF_IP_PRI_LAST = INT_MAX, };
net_device reprezintă dispozitivul (interfața de rețea) pe care se dorește realizată captura.
În momentul în care un pachet este capturat, modul de prelucrare este definit de câmpurile hooknum și hook. hooknum este tipul de hook utilizat; pentru IP, tipurile de hook-uri sunt definite în linux/netfilter.h:
enum nf_inet_hooks { NF_INET_PRE_ROUTING, NF_INET_LOCAL_IN, NF_INET_FORWARD, NF_INET_LOCAL_OUT, NF_INET_POST_ROUTING, NF_INET_NUMHOOKS };
hook este handler-ul apelat in momentul capturării unui pachet de rețea (pachet transmis în forma unei structuri struct sk_buff). Câmpul priv reprezintă o informație privată transmisă handler-ului. Prototipul handler-ului de captură este definit de tipul nf_hookfn:
struct nf_hook_state { unsigned int hook; u_int8_t pf; struct net_device *in; struct net_device *out; struct sock *sk; struct net *net; int (*okfn)(struct net *, struct sock *, struct sk_buff *); }; typedef unsigned int nf_hookfn(void *priv, struct sk_buff *skb, const struct nf_hook_state *state);
În cazul funcției de captură de tipul nf_hookfn, câmpul priv reprezintă informația privată cu care a fost inițializată structura de tipul struct nf_hook_ops. skb este pointer la pachet-ul de rețea capturat; pe baza informațiilor din skb se iau deciziile de filtrare a pachetului. Parametrul state al funcției reprezintă informațiile de stare legate de captura pachetului, incluzând interfața de intrare, interfața de ieșire, prioritatea, numărul hook-ului. Prioritatea și numărul hook-ului sunt utile pentru a permite ca aceeași funcție să fie apelată de mai multe hook-uri.
Un handler de captură poate întoarce una din constantele NF_*:
/* Responses from hook functions. */ #define NF_DROP 0 #define NF_ACCEPT 1 #define NF_STOLEN 2 #define NF_QUEUE 3 #define NF_REPEAT 4 #define NF_STOP 5 #define NF_MAX_VERDICT NF_STOP
NF_DROP este folosit pentru a filtra (ignora) un pachet, iar NF_ACCEPT este folosit pentru a accepta un pachet și a-l transmite mai departe.
Înregistrarea/deînregistrarea unui hook se realizează cu ajutorul funcțiilor definite în linux/netfilter.h:
/* Function to register/unregister hook points. */ int nf_register_net_hook(struct net *net, const struct nf_hook_ops *ops); void nf_unregister_net_hook(struct net *net, const struct nf_hook_ops *ops); int nf_register_net_hooks(struct net *net, const struct nf_hook_ops *reg, unsigned int n); void nf_unregister_net_hooks(struct net *net, const struct nf_hook_ops *reg, unsigned int n);
struct sk_buff dat ca parametru într-un hook netfilter. În timp ce antetul IP poate fi obținut de fiecare dată folosind ip_hdr(), antetele TCP și UDP pot fi obținute cu tcp_hdr(), respectiv udp_hdr() numai pentru pachete care pornesc dinspre sistem, și nu pentru cele care intră. În cazul din urmă, trebuie calculat manual offset-ul antetelor în pachet:
// Pentru pachete TCP (iph->protocol == IPPROTO_TCP) tcph = (struct tcphdr*)((__u32*)iph + iph->ihl); // Pentru pachete UDP (iph->protocol == IPPROTO_UDP) udph = (struct udphdr*)((__u32*)iph + iph->ihl);
Acest cod funcționează în toate situațiile de filtrare, și astfel este recomandată folosirea lui în locul funcțiilor de acces la antete.
Un exemplu de utilizare a unui hook netfilter este prezentat mai jos:
#include <linux/netfilter.h> #include <linux/netfilter_ipv4.h> #include <linux/net.h> #include <linux/in.h> #include <linux/skbuff.h> #include <linux/ip.h> #include <linux/tcp.h> static unsigned int my_nf_hookfn(void *priv, struct sk_buff *skb, const struct nf_hook_state *state) { /* process packet */ //... return NF_ACCEPT; } static struct nf_hook_ops my_nfho = { .hook = my_nf_hookfn, .hooknum = NF_INET_LOCAL_OUT, .pf = PF_INET, .priority = NF_IP_PRI_FIRST }; int __init my_hook_init(void) { return nf_register_net_hook(&init_net, &my_nfho); } void __exit my_hook_exit(void) { nf_unregister_net_hook(&init_net, &my_nfho); } module_init(my_hook_init); module_exit(my_hook_exit);
netcat
Cand se dezvolta aplicații care includ o parte de networking, una din cele mai folosite unelte este netcat. Supranumit și “Swiss-army knife for TCP/IP”, netcat permite printre altele:
- Inițierea de conexiuni TCP;
- Așteptarea unei conexiuni TCP;
- Trimiterea și primirea de pachete UDP;
- Afișarea traficului sub forma de hexdump;
- Execuția unui program la stabilirea conexiunii (de exemplu, un shell);
- Setarea unor opțiuni speciale în pachetele trimise.
Pentru a iniția o conexiune TCP:
nc hostname port
Pentru a asculta pe un port TCP:
nc -l -p port
Primirea și trimiterea pachetelor UDP se realizează adăugând opțiunea -u în linia de comandă.
Observație: numele comenzii este nc; de multe ori netcat este un alias pentru această comandă. Există și alte implementări ale comenzii netcat, unele având parametrii puțin diferiți față de implementarea clasică. Consultați man nc sau rulați nc -h pentru a vedea modul de utilizare.
Pentru mai multe informații despre netcat, citiți acest tutorial.
Resurse utile
- Understanding Linux Network Internals
