
This is an old revision of the document!
Laborator 4 - Dicţionar
Responsabili
Obiective
În urma parcurgerii acestui articol studentul va fi capabil să:
- definească tipul de date dicționar
- implementeze un dicționar folosind tabele de dispersie
- prezinte avantaje / dezavataje ale diverselor implementări de dicționare
Ce este un dicționar?
 Un dicţionar este un tip de date abstract compus dintr-o colecție de chei şi o colecție de valori, în care fiecărei chei îi este asociată o valoare.
Un dicţionar este un tip de date abstract compus dintr-o colecție de chei şi o colecție de valori, în care fiecărei chei îi este asociată o valoare.
Operația de găsire a unei valori asociate unei chei poartă numele de indexare, aceasta fiind și cea mai importantă operație. Din acest motiv dicționarele se mai numesc și array-uri asociative - fac asocierea între o cheie și o valoare.
Operația de adăugare a unei perechi (cheie-valoare) în dicționar are două părți. Prima parte este transformarea cheii într-un index întreg, strict pozitiv, printr-o funcție de hashing. În mod ideal, chei diferite mapează indexuri diferite în dicționar, însa în realitate nu se întamplă acest lucru. De aceea, partea a doua a operației de adăugare constă în procesul de rezolvare a coliziunilor.
Operații de bază
- put(key, value):
- adaugă în dicționar o nouă valoare și o asociază unei anumite chei
- dacă perechea există deja, valorea este înlocuită cu cea nouă
- remove(key):
- elimină din dicţionar cheia key (şi valoarea asociată acesteia)
- get(key):
- întoarce valoarea asociată cheii
- dacă perechea nu există, întoarce corespunzător o eroare pentru a semnala acest lucru
- has_key(key):
- întoarce TRUE dacă există cheia respectivă în dicționar
- întoarce FALSE dacă nu există cheia respectivă în dicționar
Implementare
O implementare frecvent întâlnită a unui dicționar este cea folosind o tabelă de dispersie - hashtable. Un hashtable este o structură de date optimizată pentru funcția de căutare - în medie, timpul de căutare este constant: O(1). Acest lucru se realizează transformând cheia într-un hash - un număr întreg fără semn pe 16 / 32 / 64 de biţi, etc. - folosind o funcție hash.
În cel mai defavorabil caz, timpul de căutare al unui element poate fi O(n) - dupa hash vom avea toate elementele in acelasi bucket, formand astfel o lista inlantuita care va trebui parcursa in intregime. Totuși, tabelele de dispersie sunt foarte utile în cazul în care se stochează cantități mari de date, a căror dimensiune (mărime a volumului de date) poate fi anticipat.
Funcția hash trebuie aleasă astfel încât să se minimizeze numărul coliziunilor (chei diferite care produc aceleași hash-uri). Coliziunile apar în mod inerent, deoarece lungimea hash-ului este fixă, iar obiectele de stocare pot avea lungimi și conținut arbitrare. În cazul apariției unei coliziuni, valorile se stochează pe aceeaşi poziție - în același bucket. În acest caz, căutarea se va reduce la compararea valorilor efective ale cheilor în cadrul bucket-ului.
Exemplu de hash pentru șiruri de caractere:
- hash.h
#ifndef __HASH__H__ #define __HASH__H__ // Hash function based on djb2 from Dan Bernstein // http://www.cse.yorku.ca/~oz/hash.html // // @return computed hash value unsigned int hash_fct(char *str) { unsigned int hash = 5381; int c; while ((c = *str++) != 0) { hash = ((hash << 5) + hash) + c; } return hash; } #endif //__HASH__H__
Exemplu pentru construcția de funcții hash care minimizează numărul de coliziuni
Reprezentarea internă cu liste înlănțuite
O implementare a unui hashtable care tratează coliziunile se numește înlănțuire directă - direct chaining. Cea mai simplă formă folosește câte o listă înlănțuită pentru fiecare bucket, practic un array de liste.
Fiecare listă este asociată unui anumit hash.
- inserarea în hashtable presupune găsirea indexului corect și adăugarea elementului la lista corespunzătoare.
Dacă dimensiunea array-ului este exprimată în puteri ale lui 2, se mai poate folosi şi formula următoare → index = hash & (HMAX - 1).
HMAX reprezintă dimensiunea maximă a array-ului.
- ștergerea presupune căutarea și scoaterea elementului din lista corespunzătoare.
- cautarea presupune determinarea index-ului prin funcția de hashing și apoi identificarea perechii potrivite.
- has_key presupune determinarea existenței unei chei în dicționar
void put(key, value, hash_table)
index <- hash(key) % DIMENSIUNE_DICTIONAR
pentru element it in bucketul hash_table[index]
// Se itereaza prin lista inlantuita de la index, pana se
// gaseste cheia dorita; daca nu este gasita, vom insera
// un entry nou in cadrul bucketului
daca it->key == key
// Daca exista key deja in bucket
// doar se updateaza valoarea
it->value <- value
return; // Cheia a fost actualizata, iesim din functie
// Daca nu a fost gasita cheia in bucket, inseram una noua
creeaza un nou element pe baza key, value
adauga elementul in hashtable
void remove(key, hash_table)
index <- hash(key) % DIMENSIUNE_DICTIONAR
pentru element it in bucketul hash_table[index]
daca it->key == key
break
// it va pointa ori dupa ultimul element (hash_table.end) => nu avem ce sterge
// ori catre un element deja existent in bucket => stergem elementul it
daca it nu indica finalul listei
sterge elementul de la pozitia lui it
TypeValue get(key, hash_table)
index <- hash(key) % DIMENSIUNE_DICTIONAR
pentru element it in bucketul hash_table[index]
daca it->key == key
return it->value
return null
bool has_key(key, hash_table)
index <- hash(key) % DIMENSIUNE_DICTIONAR
pentru element it in bucketul hash_table[index]
daca it->key == key
return true
return false
Avantajul tabelelor de dispersie constă în faptul că operația de ștergere este simplă, iar redimensionarea tabelei poate fi amânată mult timp, deoarece performanța este suficient de bună chiar și atunci când toate pozițiile din hashtable sunt folosite.
Dezavantajele acestei soluții sunt cele moștenite de la listele înlănțuite: pentru stocarea unor date mici, overhead-ul introdus poate fi semnificativ, iar parcurgerea unei liste este costisitoare.
Există și alte structuri de date cu ajutorul cărora se poate implementa un hashtable ca mai sus. Un exemplu ar fi un arbore binar de căutare echilibrat, pentru care timpul, pe cazul cel mai defavorabil, se poate reduce la O(log n) față de O(n). Totuși, această variantă se poate dovedi ineficientă dacă hashtable-ul este proiectat pentru puține coliziuni.
Un alt mod de a utiliza o listă inlanțuită pentru crearea unui dicționar presupune folosirea linear probing. Atunci când la inserarea unei perechi (cheie-valoare) în dicționar apărea o coliziune, algoritmul caută primul “spațiu gol” și inserează acolo perechea.
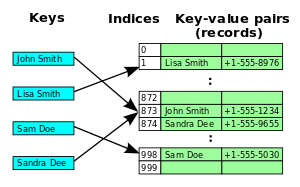
Alte reprezentări interne
- arbori binari de căutare echilibrați
- radix-tree
- prefix-tree
- array-uri judy
Acestea prezintă timpi de căutare mai buni pentru cel mai defavorabil caz și folosesc eficient spațiul de stocare în funcție de tipul de date folosit.
Schelet
Exerciţii
master al repository-ului vostru.
1) [5p] Implementaţi structura de date dicţionar, plecând de la pseudocodul de mai sus şi de la schelet.
[311CAa]
2) [2p] Studenţi
Studenții unei universități sunt memorați într-o bază de date ce are forma unui hashtable. Fiecare student este caracterizat prin nume, anul de studiu, materia preferată și nota obținută.
[1p] a. Adăugați studenții în hashtable. Comanda aferenta este adauga_studenti N, N numarul de studenti, urmand apoi N randuri cu studenti cu formatul: nume_student,an_de_studiu,materie,nota
[1p] b. Căutarea unui student dupa nume. Se va folosi comanda afiseaza_student nume.
[311CAb]
2) [2p] Movies
Un website are o baza de date in care retine filme si seriale. Un film este caracterizat de nume, regizor, anul aparitiei și rating.
[1p] a. Adăugaţi filme în hashtable. Comanda aferenta este adauga_filme N, N numarul de filme, urmand apoi N randuri cu filme cu formatul: nume_filme,regizor,an_aparitie,rating
[1p] b. Afisati toate filmele cu rating mai mic de N stele. Se va folosi comanda afiseaza_filme N.
[312CAa]
2) [2p] Bibliotecă
Cărțile dintr-o bibliotecă sunt reprezentate în sistem folosindu-se un hashtable. O carte este caracterizată prin titlu, autor, anul în care a fost publicată și statusul (la raft sau împrumutată).
[1p] a. Adăugaţi cărţi în hashtable. Comanda aferenta este adauga_carte N, N numarul de carti, urmand apoi N randuri cu carti cu formatul: titlu,autor,an_publicare,status
[1p] b. Afișarea tuturor cărților scrise de autorul famous_author. Se va folosi comanda afiseaza_carti famous_author. Nu parcurgeți toate intrările din hashtable! (HINT: Este de ajuns hashtable-ul curent?)
[312CAb]
2) [2p] Adrese
O firma de imobiliare folosește un hashtable pentru a memora imobilele pe care le administrează. Un astfel de imobil este caracterizat de numele strazii, numarul, anul în care a fost construit si numarul de camere.
[1p] a. Adăugaţi imobile în hashtable. Comanda aferenta este adauga_imobil N, N numarul de imobile, urmand apoi N randuri cu imboile cu formatul: adresa,,an_publicare,status
[1p] b. Verificarea disponibilității casei de la adresa nume_adresa. Se va folosi comanda verifica_adresa nume_adresa. Dacă nu locuiește nimeni la această adresă, afișați “Omg! You can move in right now!”, altfel, afișați “Your dream house is no longer available”.
[313CAa]
2) [2p] UEFA
Site-ul UEFA se pregăteşte să publice cea mai bună echipă a tuturor timpurilor. Baza de date este ținută sub forma unui hashtable. Un fotbalist este caracterizat prin nume, naţionalitate, poziția pe care a jucat, cel mai important trofeu câştigat şi un rating. În cazul atacanţilor şi mijlocaşilor se contorizează numărul de goluri marcate și assist-uri iar în cazul portarilor şi al fundașilor se contorizează numărul de meciuri fără gol primit și tackling-uri reușite.
[1p] a. Adăugați cel puţin 5 jucători în hashtable. Cel puţin unul dintre aceştia trebuie să aibă un rating mai mare de 200 şi cel puţin un jucător trebuie să aibă un rating mai mic de 200.
[1p] b. Afişarea informaţiilor despre un jucător
[1p] c. Eliminați din hashtable fotbaliștii cu rating mai mic de 200.
[1p] d. Afișați cei mai buni jucători din țara <country_query>. Nu parcurgeți toate intrările din hashtable! Hint: Este de ajuns hashtable-ul curent?
[313CAb]
2) [2p] Recipes
O mini-carte de rețete este memorată într-o bază de date ce are forma unui hashtable. Fiecare rețetă este caracterizată prin nume și o listă de ingrediente.
[1p] a. Adăugaţi cel puţin 5 reţete în hashtable. Cel puţin o reţetă trebuie să folosească mai mult de 5 ingrediente şi cel puţin o reţetă trebuie să folosească mai puţin de 5 ingrediente. Exemplu orientativ: HASH = 0: Bomboane cu lapte: apa, zahar, smantana | Chec: oua, faina, zahar, unt, lapte, cacao | HASH = 1: HASH = 2: Mamaliga: apa, sare, malai | MBS: apa, sare, malai, branza, smantana | Bruschete: rosii, usturoi, busuioc, ulei de masline, ceapa, sare, bagheta |
[1p] b. Căutarea unei rețete din schelet în hashtable. Se va afișa lista de ingrediente în cazul în care este găsită sau “I don’t know how to cook this”, în caz contrar.
[1p] c. Afișarea tuturor preparatelor care conțin un anumit ingredient. Nu parcurgeți toate intrările din hashtable! (Hint: Este de ajuns hashtable-ul curent)?
[1p] d. Eliminarea tuturor reţetelor care au mai mult de 5 ingrediente.
[314CAa]
2) [2p] Bancă
The Trans-Dimensional Bank folosește un hashtable pentru a memora clienții. Contul unui client este caracterizat de nume, cod pin, listă de tranzacții și o sumă de bani. O tranzacție este definită prin locație, data efectuării tranzacției și suma tranzacționată. Pentru o listă de clienți dată, implementați următoarele:
[1p] a. Adăugaţi cel puţin 5 clienţi în hashtable, iar pentru fiecare client adăugați cel puţin 2 tranzacţii. Cel puţin unul dintre clienţi trebuie să aibă mai mult de 50 de bani în cont, iar cel puţin un client trebuie să aibă mai puţin de 50 de bani în cont. Exemplu orientativ: HASH = 0: Morty Smith's transactions: 150 spent on 12-1-16 200 spent on 1-12-15 15 spent on 20-1-14 | Jerry Smith's transactions: 100 spent on 17-1-17 420 spent on 13-1-12 | HASH = 1: HASH = 2: Rick Sanchez's transactions: 500 spent on 21-7-98 100 spent on 8-8-18 | Summer Smith's transactions: 500 spent on 20-12-15 50 spent on 19-1-14 | Beth Smith's transactions: 30 spent on 15-6-18 20 spent on 16-6-18
[1p] b. Afișarea tuturor tranzacţiilor unui client dat. Exmeplu output: Rick Sanchez's transactions: 500 spent on 21-7-98 100 spent on 8-8-18
[1p] c. Eliminarea din hashtable a clienților care au în cont o sumă de bani mai mică de 50.
[1p] d. Afişarea tuturor tranzacțiilor dintr-o zi (Hint: e suficient un singur hashtable?)
[314CAb]
2) [2p] Studenţi (varianta 2)
Studenții unei universități sunt memorați într-o bază de date ce are forma unui hashtable. Fiecare student este caracterizat prin nume, facultatea la care este înscris, anul de studiu și media obținută.
[1p] a. Adăugați cel puțin 5 studenți în hash table. Exemplu orientativ: HASH = 0: Todd Chavez | Mr. Peanutbutter | HASH = 1: BoJack Horseman | Sarah Lynn | HASH = 2: Diane Nguyen | HASH = 3: Princess Carolyn | HASH = 4:
[1p] b. Căutarea unui student după nume. Se va afișa “Studentul <nume_student> este înscris la facultatea <facultate_student> și are media <nota_student>.” în cazul în care este găsit sau “Studentul <nume_student> nu a fost găsit!”, în caz contrar.
[1p] c. Afişaţi toţi studenţii care sunt înscrişi la o anumită facultate. Nu parcurgeți toate intrările din hashtable! (HINT: Este de ajuns hashtable-ul curent?)
[1p] d. Eliminați din hashtable toţi studenţii care au o medie mai mică decât valoarea medie a mediilor studentilor de la facultatea lor.
[315CAa]
2) [2p] [Magazin]
Un magazin stochează date despre produsele pe care le vinde într-o bază de date implementată ca hashtable. Fiecare produs este caracterizat prin nume, categorie, pret, număr vânzări.
[1p] a. Adăugați cel puțin 5 produse în hashtable din cel puţin două categorii diferite.
[1p] b. Căutarea unui produs după nume. Se va afișa “Produs: <nume_produs>; Categorie: <nume_categorie>; Pret: <pret_produs>; Nr vanzari: <nr_vanzari_produs>” în cazul în care este găsit sau “Produsul <nume_produs> nu face parte din oferta magazinului.”, în caz contrar.
[1p] c. Afişaţi toate produsele dintr-o anumită categorie. Nu parcurgeți toate intrările din hashtable! (HINT: Este de ajuns hashtable-ul curent?)
[1p] d. Eliminați din hashtable toate produsele care au un număr de vânzări mai mic strict decât media vânzărilor produselor din categoria lor.
[315CAb]
2) [2p] Garaj
Un service auto stochează date despre maşinile clienţilor într-o bază de date implementată ca hashtable. Fiecare maşină este caracterizat prin număr de înmatriculare, proprietar şi status (maşina e reparată sau aşteaptă ca un mecanic s-o verifice).
[1p] a. Adăugați cel puțin 5 maşini în hashtable. Cel puţin o maşină trebuie să aibă statusul de “reparată” şi cel puţin una trebuie să aibă statusul de “în aşteptare”. Cel puţin 2 maşini trebuie să aibă acelaşi proprietar.
[1p] b. Căutarea unei maşini după numărul de înmatriculare. Se va afișa “Maşina: <numar_inmatriculare>; Proprietar: <nume_proprietar>; Status: <status_masina>” în cazul în care este găsită sau “Masina <numar_inmatriculare> nu se afla in service.”, în caz contrar.
[1p] c. Afişaţi toate maşinile din baza de date care sunt deţinute de un acelaşi proprietar specificat. Nu parcurgeți toate intrările din hashtable! (HINT: Este de ajuns hashtable-ul curent?)
[1p] d. Eliminați din hashtable toate maşinile care au fost deja reparate (pe baza statusului).
[2p] (bonus). Implementați și testați redimensionarea unui hashtable: funcția resize dublează dimensiunea structurii interne a tabelei de dispersie. Dublarea se va face în momentul în care raportul dintre numărul de elemente introduse în hashtable şi numărul de bucket-uri HMAX este mai mare decâti o valoare aleasă (ex: size / HMAX > 0.75). Comportamentul dorit pentru această funcţionalitate este următorul: se redimensionează array-ul de bucket-uri, iar apoi fiecare bucket este parcus în ordine și elementele sunt redistribuite după valoarea noului hash.
Interviu
Această secțiune nu este punctată și încearcă să vă facă o oarecare idee a tipurilor de întrebări pe care le puteți întâlni la un job interview (internship, part-time, full-time, etc.) din materia prezentată în cadrul laboratorului.
- Pentru o colecție de date cu nume, prenume și multe alte câmpuri, cum ai defini funcția hash?
- Care este complexitatea unei operatiuni de căutare într-un hashtable?
- Care este diferența dintre un hashtable și un vector?
- Descrie cum ai implementa DEX cu ajutorul unui hashtable.
- În ce condiții căutarea într-un hashtable ar putea să nu fie constantă?
Bibliografie
