

Laborator 01: Scripting, plotting, tracing
Introducere în Jupyter notebook si matplotlib
Pe parcursul laboratoarelor, vom dori sa agregam si sa sumarizam rezultatele rularii scripturilor de ns-3 sub forma unor grafice, urmand ca apoi sa interpretam aceste grafice.
In general, workflow-ul unui laborator va arata astfel:

Rularea succesiva cu argumente variabile/dinamice va putea fi automatizata prin intermediul unui script Bash. In mod ideal, acest script ar trebui sa salveze datele de interes intr-un fisier (.CSV preferabil) pentru a putea fi folosit ulterior pentru a obtine grafice.
Pentru realizarea graficelor, ne vom folosi de limbajul Python, de modulul de Python matplotlib si eventual de pachetul Jupyter Notebook pentru o vizualizare mai usoara a graficelor. Jupyter Notebook este o aplicatie care porneste un server web local si care permite rularea de cod (Python, Java, etc) in cadrul unei pagini web locale care poarta numele de notebook. O variantă
specifică VScode este rularea celulelor de tip notebook direct din Python
A. Python cells în VScode
* Codul Python poate fi organizat în secțiuni care pot fi rulate independent în python, dacă sunt prefixate de
# %%
- în vscode, cu <Ctrl>+<Enter> se poate reevalua celula curentă
- Avantajul este că nu mai e necersară folosirea jupyter, iar codul python poate deasemenea fi rulat de la prompt
python3 ./plot.py
B. Jupyter notebook
Pentru a lansa aplicatia de Jupyter Notebook, rulati urmatoarea comanda:
student@isrm-vm-2020:~$ jupyter-notebook
Aceasta comanda va porni serverul web care sta in spatele aplicatiei. Pentru a putea accesa pagina de baza a serverului web in browser, exista doua variante:
- pornirea serverului web duce si la deschiderea automata a unui tab in browser-ul default al calculatorului, tab care va va conduce catre pagina de baza a serverului web
- in cazul putin probabil in care nu a fost deschis un tab in mod automat, la pornirea aplicatiei vor fi logate in consola mesaje similare cu:
To access the notebook, open this file in a browser:
file:///home/student/.local/share/jupyter/runtime/nbserver-5314-open.html
Or copy and paste one of these URLs:
http://localhost:8888/?token=ca54fe5b73bc1eb1f51f2f209e99eabb69117fd73664b721
Odata intrati pe pagina web, putem trece la crearea unui notebook (butonul New → Python3)
Plotarea datelor simple
La început, vom analiza un fișier de date. Acesta poate fi un fișier text care conține datele ca coloane. Descarcati fișierul de date numit plotting_data1.csv ce conține:
- plotting_data1.csv
# comentarii # X Y 1 2 2 3 3 2 4 1
Pe baza acestor date, graficul poate fi construit folosind urmatorul template (pe care il puteti folosi si la restul laboratoarelor):
# %% plot.py exemplu plotare import copy import numpy as np import matplotlib import matplotlib.pyplot as plt # Calea absoluta catre fisierul de date din care citim # TODO - trebuie inlocuita cu calea corecta DATA_FILE = './plotting_data1.csv' columns = ['x', 'y'] # Citim datele din fisier # Argumentul delimiter precizeaza care este delimitatorul dintre coloane # Argumentul skip_header precizeaza cate linii nu vor fi citite pornind cu inceputul fisierului # Argumentul names este unul foarte util deoarece permite asocierea de nume pentru coloanele din fisier si # de asemenea duce la un acces foarte usor al datelor in script. In acest exemplu, names va fi egal cu ['x', 'y'] # ceea ce inseamna ca putem accesa valorile din prima coloana prin sim_data['x']. # Argumentul dtype setat specifica modul in care vor fi interpretate coloanele (string-urile ca string-uri, float-urile ca float-uri). # In absenta acestui argument, valorile din coloane vor fi interpretate ca float. sim_data = np.genfromtxt(DATA_FILE, delimiter=' ', skip_header=2, names=columns, dtype=None) # %% def plot_data(sim_data): data = copy.deepcopy(sim_data) # Apelul subplots poate fi folosit pentru a crea mai multe subgrafice in cadrul aceluiasi grafic sau in cadrul unor grafice diferite # Prin figsize se specifica dimensiunea graficului fig, ax = plt.subplots(figsize=(12,12)) # Valori stilistice pentru grafic ax.grid(color='b', alpha=0.5, linestyle='dashed', linewidth=0.5) # Denumirile axelor Ox si Oy, precum si titlul graficului plt.xlabel('X values') plt.ylabel('Y values') plt.title('A very nice looking plot') # Aici este construit efectiv graficul. Campul label va fi folosit in cadrul legendei graficului ax.plot(data['x'], data['y'], label='My plot') ax.legend() plt.show() # dacă nu rulăm interactiv, în loc de show() putem salva plotul # plt.savefig('plot.png') # %% if __name__ == '__main__': plot_data(sim_data)
Introduceti acest snippet code in notebook cu mentiunea de a corecta calea data de variabila DATA_FILE. In urma rularii codului in notebook (butonul Run), imaginea rezultată este:
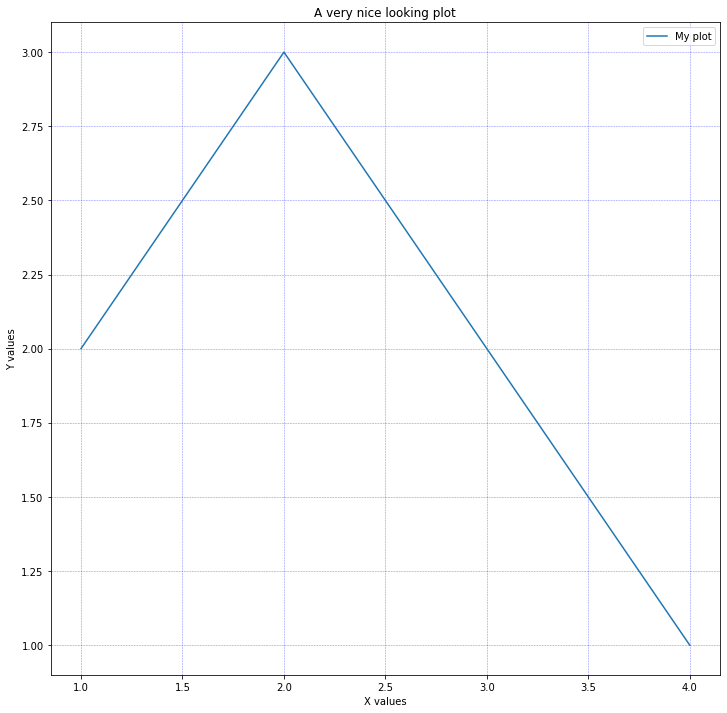
Pentru a include mai multe subgrafice in cadrul aceluiasi grafic, este suficient sa apelam ax.plot pentru fiecare subgrafic nou:
...
ax.plot(data['x'], data['y'], label='My plot')
ax.plot(data['y'], data['x'], label='My secondary plot')
...
Date cu erori
O necesitate frecventă este reprezentarea datelor cu bare de erori pentru a indica de exemplu comportarea funcției într-un punct. În următorul exemplu avem măsurători ale puterii pentru o rezistență dată, stocate în formatul: r, P, Perror care poate semnifica eroarea de măsurare a puterii:
- battery.csv
# X Y stddev 50.000000 0.036990 0.007039 47.000000 0.036990 0.007039 44.000000 0.038360 0.007053 41.000000 0.042160 0.007050 38.000000 0.043200 0.007018 35.000000 0.046900 0.007021 32.000000 0.048840 0.006963 29.000000 0.052000 0.006929 26.000000 0.055470 0.006947 23.000000 0.060000 0.006882 20.000000 0.064660 0.006879 17.000000 0.069600 0.006936 14.000000 0.079800 0.007080 11.000000 0.086920 0.007232 8.000000 0.085500 0.007262 5.000000 0.101260 0.008415 2.000000 0.091000 0.011203 0.000000 0.081480 0.011828
Vom plota astfel:
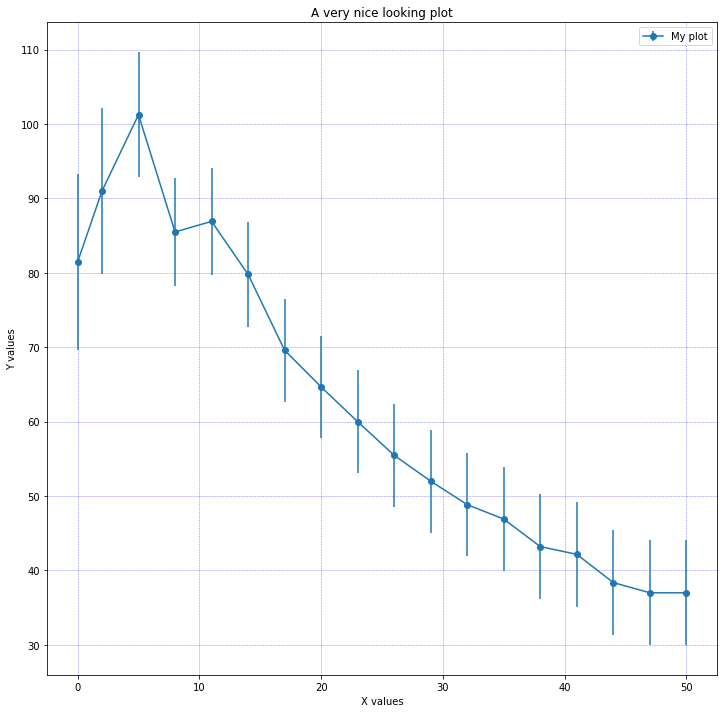
# %% plot_battery.py to plot data in battery.csv import copy import numpy as np import matplotlib import matplotlib.pyplot as plt # Calea absoluta catre fisierul de date din care citim # TODO - trebuie inlocuita cu calea corecta DATA_FILE = './battery.csv' #columns = ['resistance', 'power', 'power_error'] # %% # Citim datele din fisier ca și cum nu am avea numele coloanelor sim_data = np.genfromtxt(DATA_FILE, delimiter=' ', skip_header=2, dtype=None) # %% def plot_data(sim_data): data = copy.deepcopy(sim_data) fig, ax = plt.subplots(figsize=(12,12)) ax.grid(color='b', alpha=0.5, linestyle='dashed', linewidth=0.5) plt.xlabel('X values') plt.ylabel('Y values') plt.title('A very nice looking plot') # columns are 0=resistance, 1=power, 2=error ax.errorbar(data[:,0], 1000*data[:,1], yerr=1000*data[:,2], fmt='-o', label='My plot') ax.legend() #plt.savefig('plot_battery.png') plt.show() if __name__ == '__main__': plot_data(sim_data)
Valorile puterii sunt stocate în Watt în fișierul de date, dar au
valori mai mici decât 1. De aceea dorim să folosim mW ca unitate de
măsură.
MS Teams assignments
In cadrul laboratoarelor de ISRM, vom folosi MS Teams assignments pentru a urca rezolvarile exercitiilor, pentru a primi feedback pe rezolvari/interpretari si pentru a primi nota pe laborator.
Fisierele de interes care vor trebui urcate in MS Teams incepand cu al doilea laborator sunt urmatoarele:
- scripturi bash sau alte fisiere prin care automatizati rularea. Va exista un fișier run.sh care rulează toate subpunctele și generează toate graficele.
- fisierele de output in care salvati rezultatele obtinute in urma rularii scripturilor
- notebook-ul Jupyter aferent sau scripturile .py asociate fiecărui subpunct
- graficele obținute - fisiere .png (incluse în notebook dacă se merge pe acea variantă)
- un fisier README in care interpretati/analizati rezultatele obtinute
- exemplu fișier run.sh
# data generation, specific to each lab: cp ~/Downloads/plotting_data1.csv . cp ~/Downloads/battery.csv . # generating graphs in png files python3 ./plot.py python3 ./plot_battery.py
- pregătirea arhivei de submis:
cd ns-3-dev zip -r lab01-NUME-Prenume.zip ./lab01 adding: lab01/ (stored 0%) adding: lab01/run.sh (stored 0%) adding: lab01/plot_battery.png (deflated 25%) adding: lab01/plot.py (deflated 52%) adding: lab01/plotting_data1.csv (deflated 25%) adding: lab01/battery.csv (deflated 65%) adding: lab01/plot_battery.py (deflated 43%) adding: lab01/README.md (stored 0%) adding: lab01/plot.png (deflated 24%)
- upload lab01-NUME-Prenume.zip
Prelucrarea datelor în linie de comandă
Resurse
- Learning Bash Scripting for Beginners - Here are a list of tutorials and helpful resources to help you learn bash scripting and bash shell itself.
Filtrarea datelor
Pentru a extrage primele sau ultimele linii dintr-un output mare folosim head și tail:
student@isrm-vm:~$ dmesg | head -n 20 student@isrm-vm:~$ dmesg | tail -n 50
Putem extrage folosind sed explicit anumite linii. De exemplu din fișierul students.csv vrem liniile 10-16:
student@isrm-vm:~$ cat students.csv | sed -n '10,16p;17q'
Putem extrage informații structurate pe linii și coloane folosind utilitarul cut:
student@isrm-vm:~$ cat /etc/passwd | cut -d':' -f1,6 | head -3 root:/root daemon:/usr/sbin bin:/bin
Utilitarul awk permite aceleași acțiuni ca și cut, dar funcționalitatea sa este mai extinsă. Spre exemplu, awk poate folosi o expresie regulată ca delimitator, pe când cut acceptă un singur caracter:
student@isrm-vm:~$ netstat -i Kernel Interface table Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg eth0 1500 0 1955 0 0 0 521 0 0 0 BMRU lo 65536 0 359 0 0 0 359 0 0 0 LRU student@isrm-vm:~$ netstat -i | cut -d' ' -f1,2 Kernel Interface Iface eth0 lo student@isrm-vm:~$ netstat -i | awk -F' *' '{print $1,$2,$4}' Kernel Interface Iface MTU RX-OK eth0 1500 2029 lo 65536 359
Awk este considerat un fel de limbaj de programare ce vizează procesarea text.
Există script-uri awk complexe ce se aseamănă programelor C.
Printre altele, awk permite implementarea și apelarea de funcții. AWK (K vine de la Kernighan) este mic, simplu, și rapid, spre deosebire de perl sau python. Nu poți face tot ce faci în perl/python, dar poți face foarte ușor multe taskuri de procesare de text. Are o sintaxă apropiată de C, dar preferă datele organizate pe coloane, ca foarte multe date în rețelistică: trace-uri de simulare, tcpdump, loguri, etc. Un mare avantaj este ca poate fi rulat direct de pe linia de comandă,
fără a mai folosi un script separat - de multe ori apare într-un pipeline cu cat, sed, tr.
- În cazul cel mai des întâlnit, se specifică un program care este rulat succesiv pentru fiecare linie de intrare:
cat trace.out | awk '{print $2}'
afișează coloana a doua a fiecărei linii. De exemplu, pentru acest fișier:
- trace.out
10 2 0.2 11 3 0.3 12 2 0.2 13 3 0.1 14 4 0.05
cat trace.out | awk '{print $1+$2, $2 $3, i++;}'
produce
12 20.2 0 14 30.3 1 14 20.2 2 0 3 16 30.1 4 18 40.05 5
- Din acest exemplu se observă că:
- caracterul
$trebuie protejat de shell - separatorul implicit este (tab|spațiu)+
- variabilele sunt inițializate la 0, și își păstrează valoarea de la o linie la alta
- câmpurile inexistente ale unei linii sunt șirul vid
- tipurile sunt slabe - int, float, string, din context
- spațiu este operator de concatenare pe stringuri
cat trace.out | awk 'NF==3 { s+=$3; n++} /1[2-3]/{print $0} END{print n, s/n}'
produce
12 2 0.2 13 3 0.1 5 0.17
- Din acest exemplu se observă că:
- există variabile predefinite NF= number of fields(each line); NR=number of records;
$0= toată linia - se pot rula mai multe programe per linie, dacă sunt activate de condiții logice/regex. Pentru o linie se execută TOATE programele care se pot activa.
- există secțiunea BEGIN{} care se rulează o singură dată înainte de input, și END{} la sfârșit
- sunt disponibile multe funcții de bibliotecă: printf, sqrt, substr, xor - vedeți man awk
Structuri condiționale în shell scripting
#!/bin/bash T1="foo" T2="bar" if [ "$T1" = "$T2" ]; then echo expression evaluated as true else echo expression evaluated as false fi
Script pentru a afișa doar studenții care au media > 5 din acest fisier students.csv
#!/bin/bash IFS=',' while read name group final_grade test_grade practical_grade; do if test "$final_grade" -gt 5; then echo "$name,$group,$final_grade" fi done < students.csv
Pașii de mai sus puteau fi realizați și cu ajutorul comenzii cut. Dar, în cazul parsării folosind construcția while read avem două avantaje:
- putem afișa coloanele în ce ordine dorim;
cutpermitea afișarea de coloane doar în ordinea din fișierul de intrare; - putem prelucra în continuare, în cadrul construcției
while readinformația parsată. Spre exemplu, afișarea poate avea forma "Studentul ... face parte din grupa ...".
În bash există și construcții de tipul for. Un exemplu comun este acela de a itera prin conținutul unui
director și de a face prelucrări asupra fișierelor.
Spre exemplu, dorim să facem backup tuturor fișierelor dintr-un director trimis ca parametru în script:
#!/bin/bash for file in $1/* do if test -f $file; then stat --print="%a %F %n\n" $file cp $file $file.bkp fi done
Se poate itera și pe output-ul unei comenzi:
#!/bin/bash cd ~ unzip media.zip cd media for file in $(find . -iname '*.jpg') do echo $file done
Aritmetica în shell scripting
Bash face toate calculele pe integer, deci nu poate fi folosit pentru a calcula medii (mean, median, standard deviation).
$ x=5; echo $(($x / 3)) 1
$ x=24 $ y=25 $ b=`expr $x = $y` # Test equality. $ echo "b = $b" # 0 ( $x -ne $y ) b = 0
Putem folosi utilitarul bc cu pipe pentru calcule în floating point:
$ echo '6.5 / 2.7' | bc 2 $ echo 'scale=3; 6.5/2.7' | bc 2.407
$ awc() { awk "BEGIN{print $*}"; } $ for i in `seq 1 1 4`; do awc "$i + sqrt($i)"; done 2 3.41421 4.73205 6
Procesare multicore
Majoritatea graficelor pe care dorim sa le plotăm se folosesc de același script de simulare pe care îl rulăm cu parametri diferiți, iar la final recoltăm din outputul lui una sau mai multe valori. Dacă simularea nu folosește resurse temporare care pot duce la race conditions, se poate rula în paralel pentru a putea folosi core-urile existente. Utilitarul GNU parallel este potrivit pentru acest job, întrucât detectează automat numărul de core-uri, și are multe opțiuni pentru scriptare (nu toate naturale).
Exemple simple:
$ parallel echo "{1} a{2}" ::: $(seq 1 1 3) ::: $(seq 100 102) 1 a100 1 a101 1 a102 2 a100 2 a101 2 a102 3 a100 3 a101 3 a102
Un gotcha este rularea mai multor comenzi shell care este posibilă doar prin înglobarea lor într-o funcție sau script separat:
$ cat > batch sleep $1 echo $2 $ parallel ./batch ::: $(seq 3 -1 1) ::: $(seq 100 102) 100 100 101 102 100 101 101 102 102
Un altul este afișarea rezultatelor taskurilor în ordine secvențială, nu atunci când se termină fiecare:
$ parallel -k bash ./batch ::: $(seq 3 -1 1) ::: $(seq 100 102) 100 101 102 100 101 102 100 101 102
Exemplu care poate fi adesea refolosit în acest semestru:
$ function run_fixed(){
echo -n "$1 $2 "
./waf --run "lab6-7-cw --payloadSize=212 --ns=$1 --nd=$1 --minCw=$2 --maxCw=$2 --pcap=false" | tail -n1
}
$ export -f run_fixed
$ parallel -k run_fixed {1} {2} ::: 4 6 7 20 40 ::: 3 7 15 31 63 127 255 511 1023 2047 4095
Acest exemplu rulează scriptul ns3 pentru toate combinațiile de parametri minCw si maxCw listate în secventele separate de ::: Opțiunea -k asigură afișarea rezultatelor în ordine, chiar dacă în realitate se rulează în paralel pe mai multe core-uri, si unele taskuri se termină mai repede.

Task-uri
[01] Prelucrare fișiere
Folosind fișierul students.txt dorim afișarea doar a numelui studenților pentru acei studenți care au nota finală 10. Adică a treia coloana are valoarea 10.
Apoi ne propunem să realizăm un script numit extract-sort-grades pentru a afișa numele studenților, grupa și nota finală pentru acei studenți care au nota finală cuprină între 6 și 9 (inclusiv, adică valorile 6, 7, 8, 9). Adică a treia coloana să aibă valoarea cuprinsă între 6 și 9. Apoi vom sorta intrările în ordinea notei și apoi în ordinea grupei (adică dacă au aceeași notă să fie sortați în ordinea grupei).
Ca bonus, actualizați scriptul extract-name-tab astfel încât să primească argumente în linia de comandă notele: extract-name-tab 6 9.
Folosind awk (sau altă soluție) - extrageți toate notele din fișier și calculați media generală.
[02] Prelucrare fișiere (optional)
Ne propunem să afișăm grupele sortate în funcție de câți studenți din acea grupă au obținut nota 10.
Creați un script numit sort-groups-by-grade care afișează fiecare grupă și numărul de note de 10 obținute de studenții din acea grupă, separate prin virgulă (,, comma), sortate după numărul de note de 10. Sortarea să fie inversă, adică grupele cu cele mai multe note de 10 să fie primele.
Cautați în pagina de manual a bash șirul Arrays și localizați secțiunea corespunzătoare. Căutați pe Google după șirul bash arrays. Puteți da click pe link.
Acest exercițiu poate fi rezolvat și cu un one liner. Dacă folosiți corespunzător filtre de text precum cut, tr, sed, awk, grep, sort, uniq, veți putea obține aceeași soluție, fără să folosiți array-uri asociative.
Puteți folosi ca intrare fie fișierul students.txt fie fișierul students.csv
În cazul unei implementări corecte, în urma rulării scriptului veți obține output-ul:
314CC,4 311CC,3 315CC,3 313CC,2 312CC,1
Grupa 314CC este prima grupă afișată întrucât are cel mai mare număr de studenți care au obținut nota 10: 4 studenți. Grupa 312CC este ultima grupă afișată întrucât are cel mai mic număr de studenți care au obținut nota 10: 1 student.
[03] Basic plot
Având datele de mai jos:
Date,Open,High,Low,Close 10-03-16,774.25,776.065002,769.5,772.559998 10-04-16,776.030029,778.710022,772.890015,776.429993 10-05-16,779.309998,782.070007,775.650024,776.469971 10-06-16,779,780.47998,775.539978,776.859985 10-07-16,779.659973,779.659973,770.75,775.080017
Se cere graficul de mai jos:
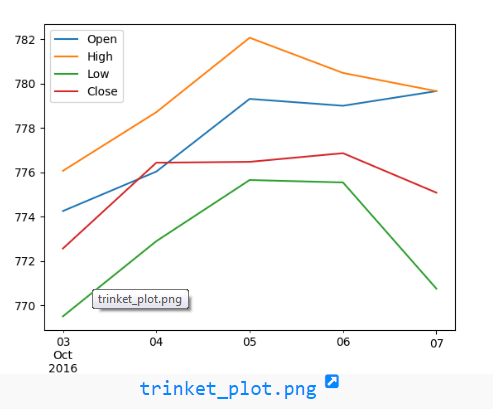
[04] Basic shell scripting (optional)
Fișierul /proc/net/dev conține toate interfețele de rețea care sunt în sistem. Iată exemplu de cum arată:
mihai@wormhole:~$ cat /proc/net/dev Inter-| Receive | Transmit face |bytes packets errs drop fifo frame compressed multicast|bytes packets errs drop fifo colls carrier compressed ens33: 401898492 1164147 0 15 0 0 0 0 387589434 843816 0 0 0 0 0 0 lo: 404014153 1015835 0 0 0 0 0 0 404014153 1015835 0 0 0 0 0 0
Fișierul /proc/net/snmp conține informații despre pachete recepționate de tip TCP/UDP pe sockeții din sistem. Iată un exemplu:
mihai@wormhole:~$ cat /proc/net/snmp Ip: Forwarding DefaultTTL InReceives InHdrErrors InAddrErrors ForwDatagrams InUnknownProtos InDiscards InDelivers OutRequests OutDiscards OutNoRoutes ReasmTimeout Re asmReqds ReasmOKs ReasmFails FragOKs FragFails FragCreates Ip: 2 64 1932581 0 4 0 0 0 1925281 1673627 20 8 0 0 0 0 0 0 0 Icmp: InMsgs InErrors InCsumErrors InDestUnreachs InTimeExcds InParmProbs InSrcQuenchs InRedirects InEchos InEchoReps InTimestamps InTimestampReps InAddrMasks InAddr MaskReps OutMsgs OutErrors OutDestUnreachs OutTimeExcds OutParmProbs OutSrcQuenchs OutRedirects OutEchos OutEchoReps OutTimestamps OutTimestampReps OutAddrMasks OutA ddrMaskReps Icmp: 46 0 0 45 0 0 0 0 0 1 0 0 0 0 41 0 40 0 0 0 0 1 0 0 0 0 0 IcmpMsg: InType0 InType3 OutType3 OutType8 IcmpMsg: 1 45 40 1 Tcp: RtoAlgorithm RtoMin RtoMax MaxConn ActiveOpens PassiveOpens AttemptFails EstabResets CurrEstab InSegs OutSegs RetransSegs InErrs OutRsts InCsumErrors Tcp: 1 200 120000 -1 4228 2576 2818 50 19 1698398 1812313 1563 5 3074 0 Udp: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors InCsumErrors IgnoredMulti Udp: 52986 40 0 21899 0 0 0 198401 UdpLite: InDatagrams NoPorts InErrors OutDatagrams RcvbufErrors SndbufErrors InCsumErrors IgnoredMulti UdpLite: 0 0 0 0 0 0 0 0
Iterați pe conținutul acestor fișiere și afișați datele într-un format cu coloane. Datele vor fi separate printr-un singur spațiu:
iface_name packets_receive packets_transmit drops_receive drops_transmit
InUdpDatagrams InUdpErrors TcpInSegs TcpRetransSegs
