

This is an old revision of the document!
Laboratorul 2
Introducere în gnuplot
Plotarea datelor rezultate din măsurători sau simulări este probabil cea mai frecventă utilizare a programului gnuplot. Gnuplot are două moduri generale de funcționare - interactiv și script. În modul interactiv, fiecare comandă este scrisa la promptul gnuplot, cu posibilitatea de a folosi la sfârsit comanda save pentru a salva comenzuile într-un script. Un script scris manual, sau obtinut cu save poate fi pasat ca parametru programului gnuplot pentru a genera grafice.
Datele discrete de intrare corespund funcțiilor date prin puncte. Avem nevoie de un fișier de date de intrare și de câteva comenzi pentru a manipula datele. Vom începe cu plotarea de bază a datelor simple și apoi vom analiza plotarea datelor cu erori.
Date simple
La început, vom analiza un fișier de date. Acesta poate fi un fișier text care c onține datele ca coloane. Considerăm fișierul de date numit plotting\_data1.dat ce conține ( gnuplot-ul ignoră liniile care încep cu diez \#):
- data1
# comentarii # X Y 1 2 2 3 3 2 4 1
Poate fi plotat scriind:
set style line 1 lc rgb '#0060ad' lt 1 lw 2 pt 7 ps 3.5 plot 'data1' with linespoints ls 1
Aici setăm tipul de punct (pt) și dimensiunea punctului
(ps), și culoarea (lc) de utilizat. Pentru stilurile de puncte și linii disponibile, puteți să
rulați comanda test la promptul gnuplot. Imaginea rezultată este
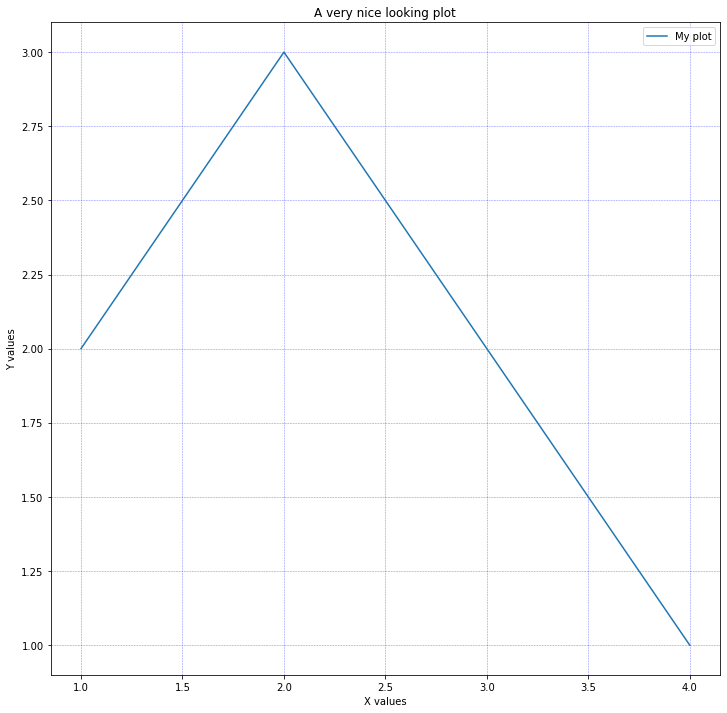
Dacă avem colecții de puncte care reprezintă date ne-continue, putem indica aceasta prin introducerea unei linii libere între date
- data2
# data2 # XY 1 2 2 3 3 2 4 1
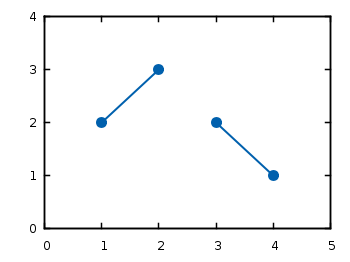
\subsection{Date simple} La început, vom analiza un fișier de date. Acesta poate fi un fișier text care c onține datele ca coloane. Considerăm fișierul de date numit plotting\_data1.dat ce conține ( gnuplot-ul ignoră liniile care încep cu diez \#): \begin{verbatim} # plotting_data1.dat # XY
1 2 2 3 3 2 4 1
\end{verbatim} Poate fi plotat scriind: \begin{verbatim} set style line 1 lc rgb '#0060ad' lt 1 lw 2 pt 7 ps 3.5 # albastru: plot 'plotting_data1.dat' with linespoints ls 1 \end{verbatim}
Aici setăm tipul de punct (pt) și dimensiunea punctului (ps) de utilizat. Pentru stilurile de puncte și linii disponibile, puteți să rulați comanda test la promptul gnuplot. Imaginea rezultată este prezentată în figura \ref{fig:gnuplot1}.
\begin{figure}
\includegraphics[width=7cm]{figures/plotting_data1.png}
\caption{Plotul datelor din plotting\_data1.dat}
\label{fig:gnuplot1}
\end{figure}
Dacă avem colecții de puncte care reprezintă date ne-continue, putem indica aceasta prin introducerea unei linii libere între date (Figura \ref{fig:gnuplot2}).
\begin{verbatim} # plotting_data2.dat # XY
1 2 2 3
3 2 4 1
\end{verbatim}
\begin{figure}
\includegraphics[width=7cm]{figures/plotting_data2.png}
\caption{Plotarea datelor din plotting\_data2.dat ca linie non-continuă}
\label{fig:gnuplot2}
\end{figure}
Dacă dorim să folosim altă culoare pentru cel de-al doilea set de date care este totuși în același fișier, putem introduce încă o linie liberă. Apoi trebuie să indexăm blocul de date începând cu comanda 'index'.
\begin{verbatim} # plotting_data3.dat # Primul bloc de date (index 0) # X Y
1 2 2 3
# Al doilea bloc de index (index 1) # X Y
3 2 4 1
\end{verbatim} Și plotăm cu comenzile: \begin{verbatim} # albastru: set line style 1 lc rgb '# 0060ad' lt 1 lw 2 pt 7 ps 3.5 # roșu: set line style 2 lc rgb '# dd181f' lt 1 lw 2 pt 5 ps 3.5 plot 'plotting-data3.dat' index 0 w lp ls 1 , \
'' indicele 1 w lp ls 2
\end{verbatim}
După cum putem vedea, am adăugat un alt tip de culoare și punct și am
reprezentat cele două seturi de date utilizând indexul și separat
parcelele cu o virgulă. Pentru a reutiliza ultimul nume de fișier,
putem scrie doar . Rezultatul este prezentat în figura 3.
\begin{figure}
\includegraphics[width=7cm]{figures/plotting_data3.png}
\caption{Plotarea datelor din plotting\_data3.dat cu două stiluri diferite.}
\label{fig:gnuplot3}
\end{figure}
\subsection{Datele cu erori}
O necesitate frecventă este reprezentarea datelor cu bare de erori
pentru a indica de exemplu comportarea funcției într-un punct. În
următorul exemplu avem măsurători ale puterii pentru o rezistență
dată, stocate în formatul: r, P, Perror care poate semnifica eroarea
de măsurare a puterii:
\begin{verbatim}
# battery.dat
# X Y stddev
50.000000 0.036990 0.007039
47.000000 0.036990 0.007039
44.000000 0.038360 0.007053
41.000000 0.042160 0.007050
38.000000 0.043200 0.007018
35.000000 0.046900 0.007021
32.000000 0.048840 0.006963
29.000000 0.052000 0.006929
26.000000 0.055470 0.006947
23.000000 0.060000 0.006882
20.000000 0.064660 0.006879
17.000000 0.069600 0.006936
14.000000 0.079800 0.007080
11.000000 0.086920 0.007232
8.000000 0.085500 0.007262
5.000000 0.101260 0.008415
2.000000 0.091000 0.011203
0.000000 0.081480 0.011828
\end{verbatim}
Vom plota astfel:
\begin{verbatim}
set xrange [ -2 : 52 ]
set yrange [ 0 : 0.12 ]
set format y '% .0s'
plot 'battery.dat' using 1:2:3 \
w yerrorbars ls 1 , \
using 1:2 w lines ls 1
\end{verbatim}
Valorile puterii sunt stocate în Watt în fișierul de date, dar au valori mai mici decât 1. De aceea dorim să folosim mW ca unitate de măsură. Așadar, am setat opțiunea de format pentru a spune gnuplot-ului să folosească “mantisa as base of current logscale”, vezi documentația gnuplot . Apoi, cu indicația {\texttt using}, se specifică gnuplot ce coloane din fișierul de date ar trebui să utilizeze. Deoarece vrem să plotăm eroarea puterii și puterea, avem nevoie de trei coloane - 1,2, și 4. Folosind stilul de plotare {\texttt yerrorbars} nu este posibilă combinarea punctelor cu o linie. Prin urmare, adăugăm o a doua linie la comanda {\texttt plot} pentru a combina punctele cu o linie. Acest lucru ne va da rezultatul din figura \ref{fig:gnuplot4}. \begin{figure}
\includegraphics[width=7cm]{figures/battery_data.png}
\caption{Plotarea datelor din battery.dat cu erori pentru axa y (putere). }
\label{fig:gnuplot4}
\end{figure} Putem evita comanda {\texttt set format} din ultimul grafic prin manipularea directă a datelor de intrare:
\begin{verbatim} set yrange [ 0:120 ] plot 'battery.dat' using 1:($2*1000):($4*1000)\
w yerrorbars ls 1
\end{verbatim}
Atenție, sunt necesare paranteze în jurul
expresiilor pe coloană, iar numărul coloanei este indicat cu \ 2*1000):(2}'</code> afișează coloana a doua a fiecărei linii. De exemplu, pentru acest fișier:
2*1000):(2}'</code> afișează coloana a doua a fiecărei linii. De exemplu, pentru acest fișier:
- trace.out
10 2 0.2 11 3 0.3 12 2 0.2 13 3 0.1 14 4 0.05
cat trace.out | awk '{print $1+$2, $2 $3, i++;}'produce
12 20.2 0 14 30.3 1 14 20.2 2 0 3 16 30.1 4 18 40.05 5
- Din acest exemplu se observă că:
- caracterul3; n++} /1[2-3]/{print 0 = toată linia
- se pot rula mai multe programe per linie, dacă sunt activate de condiții logice/regex. Pentru o linie se execută TOATE programele care se pot activa.
- există secțiunea BEGIN{} care se rulează o singură dată înainte de input, și END{} la sfârșit
- sunt disponibile multe funcții de bibliotecă: printf, sqrt, substr, xor - vedeți man awk
- Exercițiul 2: În laboratorul 1, folosiți
$tcp attach [open tcp.tr w] $tcp trace cwnd_ $tcp trace rtt_
pentru a explora relația dintre lungimea cozii la bottleneck (link n2 n3), RTT-ul perceput de TCP, și fracțiunea de debit obținută în concurență cu UDP.
- Rulați pentru valori ale cozii: 5, 15, 50
- De ce debitele obținute nu sunt stabile?
- De ce apar debite UDP mai mari ca 1Mbps?
- Care este relația dintre RTT și debite?
ns-2 wireless
Citiți ns2 wireless tutorial
Marc Greis tutorial secțiunea IX .
- Exemple de linii din trace cu newtrace:
r -t 0.016905500 -Hs 1 -Hd -2 -Ni 1 -Nx 0.00 -Ny 75.00 -Nz 0.00 -Ne -1.000000 -Nl MAC -Nw --- -Ma 0 -Md 1 -Ms 0 -Mt ACK d -t 1.804824308 -Hs 2 -Hd 2 -Ni 2 -Nx 75.00 -Ny 0.00 -Nz 0.00 -Ne -1.000000 -Nl MAC -Nw COL -Ma 13a -Md 2 -Ms 0 -Mt cbr -Is 0.0 -Id 2.1 -It cbr -Il 1590 -If 0 -Ii 144 -Iv 32 -Pn cbr -Pi 34 -Pf 0 -Po 0
- Fiecare linie descrie un eveniment de trimitere, primire, dirijare, sau dropare a unui pachet. Câmpurile cele mai importante dintr-o linie a fișierului trace sunt:
s: Send r: Receive d: Drop f: Forward -t double Time (* For Global Setting) -Ni int Node ID -Nx double Node X Coordinate -Ny double Node Y Coordinate -Nz double Node Z Coordinate -Ne double Node Energy Level -Nl string Network trace Level (AGT, RTR, MAC, etc.) -Nw string Drop Reason -Hs int Hop source node ID -Hd int Hop destination Node ID, -1, -2 -Ma hexadecimal Duration -Ms hexadecimal Source Ethernet Address -Md hexadecimal Destination Ethernet Address -Mt hexadecimal Ethernet Type -P string Packet Type (arp, dsr, imep, tora, etc.) -Pn string Packet Type (cbr, tcp) -Ps sequence number (pentru tcp, coloana 47)
- Exercițiul 3: modificați
simple-wireless.tcldin Marc Greis sec IX pentru- a utiliza noul format de trace ( cu
$ns_ use-newtrace) - a monitoriza evenimentele de la nivelele 2 și 4 (agent și MAC)
- a avea o coadă de doar 10 pachete în interfața wireless
- identificați în trace cadrele de tip CTS, ACK, ack, tcp.
- la ce moment începe transferul propriuzis (nodurile sunt suficient de aproape pentru a schimba cadre)? 1)
- Desenați o diagramă cu transferul unui segment TCP între noduri, indicând tipurile cadrelor/pachetelor.
- calculați numărul de cadre de date(tcp)pierdute de fiecare nod la nivelul 2 - MAC 2)
- calculați numărul de cadre de date(tcp)pierdute de fiecare nod la nivelul 3 - IFQ 3)
- justificați diferențele 4)
- comparați pierderile între pachetele tcp și ack 5)
- comparați pierderile între cadrele ACK și RTS 6)
- justificați diferențele
- dezactivați RTS/CTS folosind
Mac/802_11 set RTSThreshold_ 3000
și comparați performanța TCP cu cazul precendent. Sugestie: plotați evoluția în timp a numerelor de secvență 7)
cat simple.tr | grep '^r' | grep AGT | grep tcp | grep -v ack | awk '{print $3, $47}'

 47}'| head
47}'| head 